Beyond Attention: The Post-Transformer Architecture Landscape for Physical AI
Survey the post-transformer frontier—state space models, recurrent revivals, long convolutions, and equivariant networks—and see why the architectures that will power physical AI look nothing like a stack of attention layers.
W15 Trend Tutorial · Advanced (ML Practitioner) · April 2026
Research Area: Neural Architectures, Physical AI
Companion Notebooks
| # | Notebook | Focus | Compute |
|---|---|---|---|
| 00 | 00_ssm_vs_attention.ipynb | SSM (Mamba-like) vs. self-attention — sequence modeling, spatial reasoning, efficiency comparison | CPU only |
| 01 | 01_equivariant_vs_standard.ipynb | Equivariant vs. standard features — 3D point cloud classification, rotation generalization | CPU only |
1. Why This Matters Now
Transformers conquered NLP in 2017, then colonized vision, then merged into multimodal. They seem inevitable. But ask a harder question: Are transformers the right architecture for physical AI?
Physical AI systems — robotics, world modeling, autonomous vehicles — demand different inductive biases than text prediction. They must handle 3D geometry natively, process ultra-long sensor streams (100K+ tokens for robot action sequences), and generalize across spatial transformations. The cracks are showing.
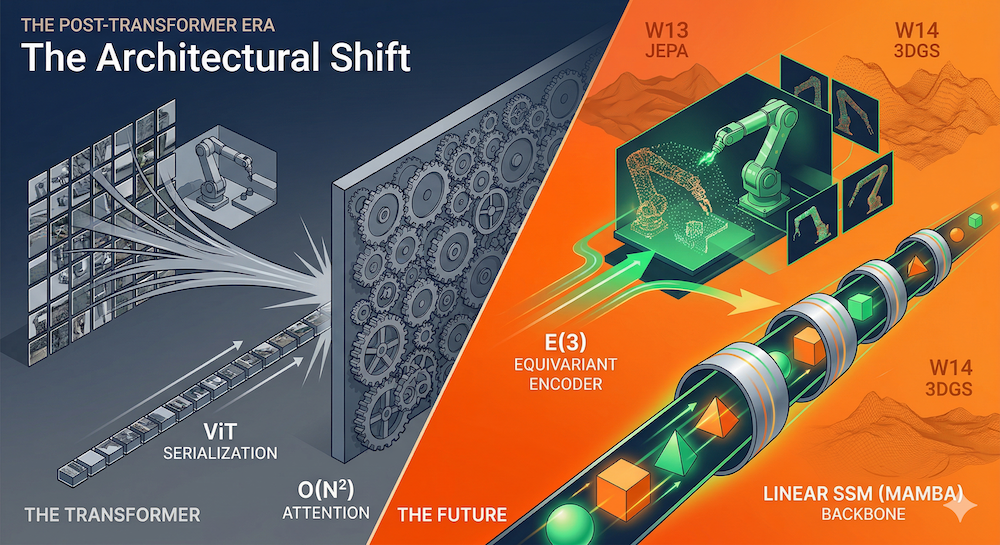
Vision Transformer (ViT) performs miracles on ImageNet, yet it solves a fundamental problem with a hack: image patches are serialized into a 1D sequence, fed through a transformer designed for language, then spatial structure must be laboriously relearned from position embeddings. For high-resolution 3D data, this becomes prohibitively expensive: quadratic attention cost scales brutally as resolution climbs.
Meanwhile, a new generation of architectures is emerging—state space models, recurrent networks, equivariant convolutions—that ask: what if we built the geometry into the architecture itself?
Compare the extremes: LeWorldModel (LeCun's recent work) encodes each video frame as a single 192-dim token; DINO-WM uses thousands. LeWorldModel achieves similar performance with ~200× fewer tokens and 48× faster planning. The win isn't marginal—it's architectural.
This week, we survey the post-transformer landscape. We'll show you that the transformer's reign is not over, but its monopoly is breaking. The future of physical AI will be hybrid, specialized, and geometrically informed.
Context: This is W15 of a three-week arc. W13 asked how we should model the world (JEPA vs. generative). W14 explored how we render and generate it (3DGS, Marble-like architectures). W15 focuses on the architecture that powers these systems. Landscape reading.
2. The Transformer's Vision Hack
Let's be precise about what ViT does and why it's a hack.
Important: Calling it a "hack" is an architectural observation, not a dismissal. ViT was one of the most influential papers of the decade — it proved that vision-specific inductive biases (convolution, pooling hierarchies) were not strictly necessary, which unlocked the multimodal foundation models we build on today. We use "hack" to describe a specific design choice (2D→1D serialization) whose limitations sharpen as the field moves toward 3D geometry and physical AI. The goal is to understand where ViT's elegance breaks down, precisely because its core insight was so powerful.
The forward pass:
- Take an RGB image (e.g., 224×224 pixels).
- Slice it into non-overlapping 16×16 patches. For a 224×224 image, that yields (224/16)² = 196 patches.
- Flatten each patch to a vector: 3 × 16 × 16 = 768 dimensions.
- Project linearly to the model dimension (e.g., 768).
- Add learned positional embeddings to recover spatial structure.
- Prepend a learnable
[CLS]token. - Pass the sequence (197 tokens) through standard transformer layers.
Why it works: Transformers are universal approximators with enough capacity. Position embeddings are flexible. Billions of images during pretraining can teach the model to encode 2D structure.
Why it's a hack:
- Geometry is discarded. The 2D spatial layout is flattened into a 1D sequence. A patch far to the left and a patch far to the right are equally "distant" in the transformer's sequence dimension—even though they're neighbors in 2D.
- Position embeddings are learned, not structural. Unlike hand-crafted 2D coordinate systems, learned embeddings must rediscover spatial relationships at each layer, for each model. This is inefficient and fragile across distribution shifts.
- Quadratic cost. Attention complexity is O(n²) in the number of patches. High-resolution images (512×512 → 1024 patches) become slow and memory-intensive. For 3D data or video, this explodes: a 10-second video at 30fps with 512×512 resolution is ~72K frames, each with 1024 patches = 73M tokens. Infeasible.
- No 3D awareness. ViT's inductive biases are purely sequential. A world model processing 3D point clouds or multi-view observations gets no structural hints that the data is inherently spatial.
The transformer's flexibility is a blessing and a curse. It can learn anything, so it must learn everything—including geometry that a better architecture would encode for free.
3. State Space Models: The Mamba Revolution
Enter state space models (SSMs)—a classical tool from control theory, recently turbocharged for deep learning.
S4: Structured State Spaces (2021)
Albert Gu, Karan Goel, and Christopher Ré introduced S4 at ICLR 2022. The core insight: classical SSMs (recurrent computations across very long sequences) can be parameterized and trained efficiently using a structured diagonalization trick.
An SSM is a linear recurrence:
where is the hidden state, is the input, and are learned matrices of compatible shape. The trick: condition with a low-rank correction and diagonalize it via Cauchy kernels. This reduces training to a convolution (parallelizable) and inference to a recurrence (linear in sequence length).
Results: S4 solved sequential CIFAR-10 at 91% with no data augmentation. On the Long Range Arena benchmark—tests requiring 1K to 16K token dependencies—S4 matched or exceeded transformer performance while being 60× faster at generation.
The payoff: linear complexity in sequence length, constant hidden state size, and a natural inductive bias for long-range dependencies.
Mamba: Selective State Spaces (2023)
But S4 has a weakness: the SSM parameters A, B, C, D are fixed across all timesteps. This makes the model passive—it processes every input identically, regardless of content.
Mamba (Gu & Dao, 2023) fixes this. Key innovation: make , , content-aware. Specifically, and (and sometimes ) are parameterized as functions of the current input — formally and . This is called a "selective" state space: the model actively decides what to memorize and what to forget based on the data.
The result: Mamba achieves transformer-level perplexity on language tasks with linear complexity and 5× higher inference throughput. It scales to very long sequences (100K+ tokens) without the quadratic attention cost.
The scan operation: Unlike attention's all-pairs interaction, Mamba processes the sequence left-to-right in a single pass (or bidirectionally, as in Vision Mamba). Each step is O(1); the recurrence is parallelizable during training via a "scan" operation.
Vision Mamba (2024)
Zhuang Liu and colleagues applied Mamba to vision: Vision Mamba. Instead of serializing image patches naively, they process them bidirectionally—left-to-right and right-to-left—to capture global context without explicit attention.
The wins are striking:
- On high-resolution images (1248×1248), Vision Mamba is 2.8× faster than DeiT.
- GPU memory usage drops 86.8% compared to DeiT on the same images.
- Beats DeiT on ImageNet classification.
- Subquadratic complexity means it scales to 1M+ token sequences.
Why? Mamba's linear complexity shines on long sequences. The bidirectional scan (forward and backward) approximates global reasoning without storing attention weights.
Why SSMs Matter for Physical AI
Consider a robot with cameras, LiDAR, IMU, and proprioception. A 10-second action sequence at 100Hz is 1000 timesteps. Add multi-modal sensor fusion and history, and you're easily at 100K tokens. Transformer's O(n²) cost makes this prohibitive; Mamba's linear cost laughs at it.
Beyond efficiency, SSMs have another virtue: they naturally handle streaming, real-time data. An inference step costs O(1) memory regardless of history length—perfect for online robot control.
4. Recurrent Renaissance: RWKV and xLSTM
The last decade dismissed RNNs. Vanishing gradients, slow training, and transformers' parallelizability seemed to seal their fate. But recurrence has advantages transformers ignore:
- Constant memory per timestep. No KV cache explosion.
- Streaming-friendly. Process a token and forget the past—O(1) state.
- Infinite context. Hidden state doesn't grow with sequence length.
A new generation of RNNs reclaims these benefits while matching transformer performance.
RWKV: Recurrent With Known Vector (2023)
RWKV (pronounced "RwaKuv") is an RNN formulation of a linear attention mechanism. Key insight: decompose attention into independent scalar operations per token, avoiding the attention matrix.
Architecture: Each token attends to all prior tokens, but via a decaying exponential kernel parameterized by token position. This mimics attention's flexibility but with RNN efficiency.
Performance: RWKV-7 (the latest variant, "Goose") achieves GPT-3 competitive perplexity at 14B parameters. Training is parallelizable like transformers; inference is RNN-efficient. Hidden state is a fixed-size vector.
Deployment: Microsoft shipped RWKV-5 ("Eagle") to 1.5 billion Windows 10 and 11 machines for Windows Copilot. On-device, energy-efficient inference was the driver. RWKV's constant memory and fast inference make it ideal for low-power scenarios.
xLSTM: LSTM Reinvented (2024)
Sepp Hochreiter, LSTM's inventor, returned with xLSTM (Extended LSTM; Beck et al., 2024). The motivation: scale LSTMs to billions of parameters using modern deep learning techniques, but avoid transformers' quadratic cost.
Key innovations:
- Exponential gating (not just tanh) with stabilization.
- Matrix memory cells (mLSTM) instead of scalar (sLSTM), with parallelizable covariance update rules.
- Improved normalization and modern training recipes.
Results: xLSTM competes with state-of-the-art transformers and SSMs on language modeling benchmarks. Importantly, compute scales linearly with sequence length—no quadratic attention.
Deployment: Hochreiter founded NXAI in 2024; the team released xLSTM-7B in December 2024. Unlike Mamba, xLSTM is an LSTM variant, so it inherits 30 years of LSTM research and engineering.
Recurrence for Physical AI
Both RWKV and xLSTM share a critical property: fixed-size hidden state. For a robot processing sensor streams continuously, this is gold. Process frame 1000, discard it, frame 1001 arrives—no accumulation of KV cache, no memory explosion.
Combine xLSTM or RWKV as a backbone with task-specific heads (e.g., action prediction for control), and you have a learnable, streaming-friendly physical world model.
5. Convolution-Based: Hyena and Beyond
If transformers are too general and state space models feel niche, what about convolution? Convolution has strong inductive biases: locality (nearby pixels matter more than distant ones) and translation equivariance (shifting the input shifts the output).
For images and spatial data, these biases are exactly right. But standard convolutions with fixed, small kernels (3×3 filters) can't capture long-range dependencies efficiently.
Hyena: Long Convolutions with Data-Dependent Gating (2023)
Poli et al. (2023) introduced Hyena, a subquadratic replacement for attention using long convolutions and gating.
Architecture: Interleave two operations:
- Implicit long convolutions: Use FFNs to parameterize convolution kernels dynamically. This gives large effective receptive fields without storing explicit weights.
- Data-dependent gating: Multiply by learned element-wise gates that depend on the input.
No attention matrix is ever computed. Yet Hyena matches attention on standard benchmarks.
Performance:
- On sequences of 1K–100K tokens, Hyena's accuracy exceeds state-space baselines by >50 points.
- 100× faster than attention at sequence length 64K.
- 20% reduction in training compute vs. transformers on language modeling (WikiText103, The Pile) at 2K token length.
- O(n log n) or better, depending on the specific kernel parameterization.
Why Convolutions for Physical AI
Convolution's locality bias is a feature, not a bug, for spatial reasoning:
- A robot's visual field naturally exhibits locality: nearby objects matter more than distant ones.
- 3D environments have spatial structure; convolutions respect it.
- Convolutions are fast on GPUs and TPUs, with decades of optimization behind them.
Hyena reclaims convolution's power while extending it to very long sequences, making it competitive with transformers and SSMs.
6. Geometric Deep Learning and Equivariant Networks
So far, we've discussed efficiency: SSMs are fast, convolutions are cheap, RNNs are streaming-friendly. But there's a deeper question: what inductive biases should we hardcode into the architecture?
Enter geometric deep learning (Bronstein et al., 2021)—a framework that builds symmetries into neural network architectures rather than forcing the model to learn them from data.
Core Idea: Equivariance
The laws of physics don't change if you rotate your coordinate system. A robot's visual perception should be the same whether the camera rotates. A world model for planetary dynamics should respect translation symmetry.
Formally, an operation is equivariant to a transformation if transforming the input and applying the operation yields the same result as applying the operation and then transforming the output.
Example: if you rotate an input image by 90°, an equivariant feature extractor produces features that are also rotated by 90°. Contrast this with an invariant operation (e.g., object classification), which ignores rotation entirely.
E(3)-Equivariant Networks
E(3) is the Euclidean group in 3D: rotations, translations, and reflections. An E(3)-equivariant network respects these symmetries. A closely related group is SE(3) (Special Euclidean), which covers rotations and translations but excludes reflections. SE(3) is often the more natural choice for robotics: a left hand is not a right hand, and a grasping policy should distinguish mirror-image configurations rather than treating them as equivalent.
Why do these groups matter? 3D robotics, molecular dynamics, autonomous vehicles—all operate in Euclidean 3D space. Building equivariance into the network means:
- The model generalizes better across rotated/translated inputs.
- It requires fewer parameters (symmetries are "built-in").
- Learned representations encode meaningful geometric quantities.
Applications:
- NequIP: E(3)-equivariant neural network interatomic potentials. Used to accelerate molecular dynamics simulations orders of magnitude faster than ab-initio methods.
- DFT Hamiltonians: Represent density functional theory wavefunctions while respecting symmetries, enabling faster electronic structure calculations.
- Robotics: Equivariant encoders for 3D point cloud perception; equivariant policy networks for robot manipulation.
Capsule Networks (Hinton, 2017) and EquiCaps (2025)
Capsule networks (Hinton, 2017) encode part-whole relationships via "pose parameters"—vectors that represent the position, size, and orientation of a feature. This is a form of explicit geometric reasoning.
Recent work: EquiCaps (2025) combines capsule networks with E(3) equivariance, yielding networks that learn hierarchical, geometric feature representations naturally suited for 3D reasoning.
Geometric Deep Learning for Physical AI
The win is conceptual and practical:
- A robot's proprioceptive sensor (e.g., joint angles) should be processed by networks that respect the symmetries of the robot's kinematics.
- A world model for 3D environments should be translation-equivariant (shifting all objects shouldn't change the dynamics).
- Equivariant networks generalize better to unseen orientations and translations—critical for robustness.
7. The Hybrid Convergence
Before diving into specific hybrids, here's the landscape at a glance:
| Architecture | Complexity | State Size | Best For | Physical AI Limitation |
|---|---|---|---|---|
| Transformer | Growing (KV cache) | Global context, NLP, multimodal fusion | Quadratic scaling; no native 3D bias | |
| SSM (Mamba) | Fixed | Long streams, robotics, real-time control | Sequential state; global random-access needs hybrid | |
| RNN (xLSTM/RWKV) | Fixed | Streaming inference, on-device deployment | Historically hard to parallelize (modern variants fix this) | |
| Long Convolution (Hyena) | Kernel-dependent | Local spatial reasoning, high-resolution vision | Limited global context without stacking | |
| Equivariant | Varies | Geometric | 3D point clouds, molecular dynamics, physics | Computational overhead; specialized to known symmetries |
The pattern is clear: no single row dominates. The frontier is hybrid.
Jamba: Transformer + Mamba + MoE (AI21, 2024)
AI21 released Jamba, a 52B model blending transformers, Mamba, and mixture-of-experts.
Design: Interleave Transformer layers with Mamba layers at a 1:7 ratio (one attention layer per seven total layers). Use sparse MoE gating so only 12B of 52B parameters activate per inference.
Results:
- 3× throughput on long contexts (256K tokens) vs. Mixtral 8x7B.
- State-of-the-art language modeling benchmarks.
- Hybrid allows attention for global, all-pairs reasoning where it's needed (early layers for broad context); Mamba for efficient, linear-cost continuation (most layers).
MambaVision: Spatial Processing with Hybridity (2024)
Vision researchers applied similar ideas: MambaVision uses Mamba early in the network (cheap, for local feature extraction) and attention later (expensive, but fewer tokens). This achieves SOTA on ImageNet while being more efficient than ViT.
JEPA's Position in the Landscape
Yann LeCun's JEPA (Joint-Embedding Predictive Architecture) is worth noting here. JEPA avoids autoregressive generation entirely, using contrastive losses on latent representations. Architecturally, it often uses ViT encoders, but the innovation is the training paradigm, not the architecture. JEPA decouples "what architecture?" from "how do we train it?"—a valuable conceptual split.
The Emerging Pattern
For physical AI, the consensus architecture looks like this:
Equivariant Encoder (3D-aware, geometry-native)
↓
SSM/Hybrid Backbone (Mamba or xLSTM for efficiency)
↓
Task-Specific Decoders (action, planning, prediction)
Early layers handle raw geometry (e.g., point clouds, multi-view images). Equivariant layers enforce symmetries. Middle layers use efficient SSMs or RNNs for sequential reasoning. Task heads specialize for control, prediction, or planning.
This is the opposite of ViT's catch-all approach. It's specialized, principled, and empirically strong.
8. What We Build This Week
Two notebooks ground this survey in code.
Notebook 00: SSM vs. Self-Attention from Scratch
Implement a minimal Mamba-like SSM and a basic transformer from pure NumPy. Compare:
- Sequence modeling: How well do they learn long-range dependencies on synthetic tasks?
- Spatial reasoning: Given a sequence of (x, y) coordinates representing a path in 2D, can the model predict the next position? Test on shifted/rotated paths (basic equivariance test).
- Efficiency: Plot FLOPs, memory, inference time as sequence length varies.
Take-away: See why SSMs scale linearly while attention explodes.
Notebook 01: Equivariant vs. Standard Features for 3D Classification
Build a simple 3D point cloud classifier. Compare:
- Standard ViT-like approach: Serialize points into a sequence, apply transformer.
- Equivariant approach: Use hand-crafted geometric features (e.g., distances, angles) or train an E(3)-equivariant encoder.
Test generalization: train on one rotation, evaluate on others. Equivariant networks should generalize; standard networks shouldn't.
Take-away: Understand why geometry matters for physical AI.
Conclusion
Transformers were designed for text, hacked into vision, and now strain under the demands of 3D geometry and ultra-long sequences. The post-transformer landscape is crowded and exciting:
- State Space Models (Mamba, S4) offer linear complexity and streaming inference.
- Recurrent networks (RWKV, xLSTM) reclaim the advantages of RNNs with modern training.
- Convolutions (Hyena) remain powerful for local, spatial reasoning.
- Equivariant networks build geometry into the architecture, not the data.
- Hybrid architectures (Jamba, MambaVision) blend multiple approaches for efficiency and expressivity.
For physical AI—robots, world models, autonomous systems—the takeaway is clear: choose the right tool for the job. Transformers are still powerful for certain tasks (e.g., language, broad multimodal fusion), but they're no longer the default. Efficient, geometrically aware, streaming-friendly architectures are ascending.
The era of one-architecture-to-rule-them-all is over. The era of principled, specialized systems has begun.
Sources & Further Reading
- Vaswani et al., 2017: Attention Is All You Need
- Dosovitskiy et al., 2020: Vision Transformers (ViT)
- Gu et al., 2021: S4 – Efficiently Modeling Long Sequences with Structured State Spaces
- Gu & Dao, 2023: Mamba – Linear-Time Sequence Modeling with Selective State Spaces
- Liu et al., 2024: Vision Mamba – Efficient Visual Representation Learning with Bidirectional State Space Models
- Poli et al., 2023: Hyena Hierarchy – Towards Larger Convolutional Language Models
- Beck et al., 2024: xLSTM – Extended Long Short-Term Memory
- AI21, 2024: Jamba – A Hybrid Transformer-Mamba Language Model
- Huang et al., 2024: MambaVision: A Hybrid Mamba-Transformer Vision Backbone
- Bronstein et al., 2021: Geometric Deep Learning: Going beyond Euclidean data
- Maas et al., 2026: LeWorldModel – Stable End-to-End Joint-Embedding Predictive Architecture from Pixels
- Zhou et al., 2024: DINO-WM – World Models on Pre-trained Visual Features enable Zero-shot Planning
- Satorras et al., 2021: E(n) Equivariant Graph Neural Networks
- Hinton et al., 2017: Dynamic Routing Between Capsules
- Zhong et al., 2025: EquiCaps – Equivariant Capsule Networks with E(3) Symmetry
- Touvron et al., 2021: Training data-efficient image transformers & distillation through attention (DeiT)
- LeCun et al., 2022: Joint-Embedding Predictive Architecture (JEPA)
- BlinkDL, 2023: RWKV-LM – GitHub Repository
- e3nn: A modular framework for neural networks with Euclidean symmetry
Stay connected:
- 📧 Subscribe to our newsletter for updates
- 📺 Watch our YouTube channel for AI news and tutorials
- 🐦 Follow us on Twitter for quick updates
- 🎥 Check us on Rumble for video content