AMI Labs vs. World Labs: Two Billion-Dollar Visions for World Models
World Models landscape and engineering challenges in 2026-2027
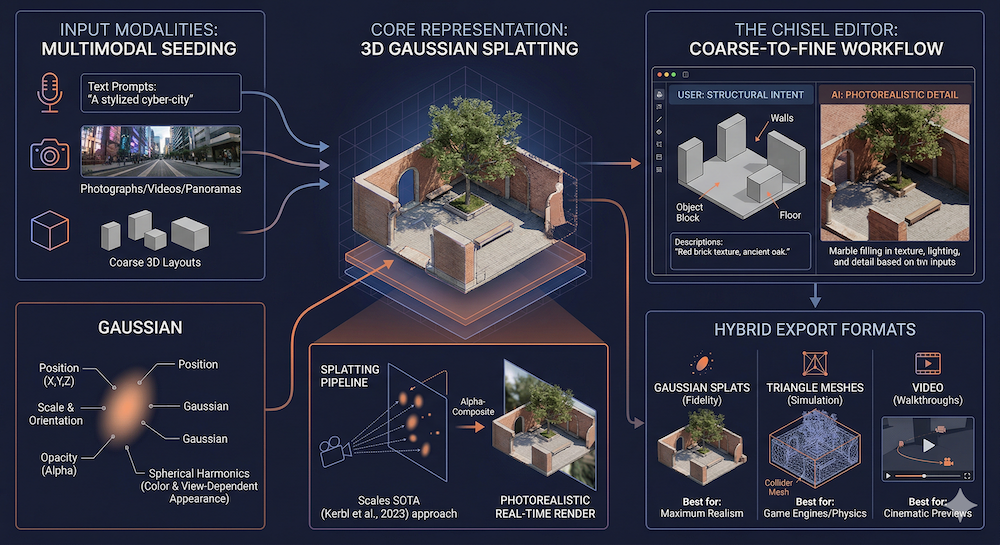
Figure: illustration of WorldLab's Marble
W13 Basic Tutorial 2 · Intermediate · March 2026
Research Area: World Models
Companion Notebooks
| # | Notebook | Focus | Compute |
|---|---|---|---|
| 00 | 00_lewm_toy_world_model.ipynb | Toy JEPA world model from scratch — encoder, predictor, SIGReg regularization | CPU only |
| 01 | 01_jepa_latent_dynamics_planning.ipynb | Latent dynamics and planning — CEM, MPC, speed benchmarks | CPU only |
Overview
World models in 2025–2026 have split into two major approaches backed by unprecedented funding. This tutorial maps the full landscape — with deep comparisons of AMI Labs (energy-based) vs. World Labs (generative), updated with this week's LeWorldModel release and Sora's shutdown.
We first covered the AMI–World Labs rivalry in our W11 blog post. This tutorial deepens that analysis with technical specifics and practical implications.
1. The $2 Billion Rivalry: AMI Labs vs. World Labs
AMI Labs: Predict, Don't Generate
AMI Labs was co-founded by Yann LeCun — founder of LeNet, Turing Award winner (2018) and former VP & Chief AI Scientist at Meta — after decades of arguing that autoregressive generation is the wrong paradigm for understanding the physical world.
Funding: $1.03 billion seed (March 2026), $3.5B pre-money valuation. Backed by Bezos Expeditions, Eric Schmidt, Mark Cuban, Xavier Niel, Tim Berners-Lee.
Team: Saining Xie (Chief Science Officer, creator of DiT — the architecture behind Sora), Pascale Fung (Chief Research & Innovation Officer), Michael Rabbat (VP of World Models), Laurent Solly (COO, formerly Meta VP Europe).
Technical approach: JEPA (Joint Embedding Predictive Architecture) — learn abstract representations of the world by predicting in latent space, never generating pixels. Train on video, audio, sensor data, and lidar.
Target applications: Industrial automation, robotics, healthcare — domains where hallucinating physics has real consequences.
The irony: AMI's Chief Science Officer created the architecture that powered Sora, the model OpenAI just killed for being too expensive. Xie's move from generative to energy-based approaches is itself a signal about where the field is heading.
World Labs: Generate the World
World Labs was founded by Fei-Fei Li — the Stanford professor who created ImageNet, the dataset that catalyzed the deep learning revolution.
Funding: $1 billion total including $200M strategic investment from Autodesk (February 2026), $5B valuation.
Product: Marble — generally available since November 2025, a generative world model that creates persistent, editable 3D environments from any input modality.
Technical approach: Generative synthesis via diffusion + 3D Gaussian splatting. Build visual worlds you can navigate, edit, and export.
Target applications: Creative tools, gaming, film, architecture, robotics simulation. Autodesk integration puts it directly into professional 3D workflows.
Head-to-Head Comparison
| Dimension | AMI Labs (LeCun) | World Labs (Fei-Fei Li) |
|---|---|---|
| Philosophy | Understanding first — representations enable reasoning | Generation first — visual worlds enable everything |
| Architecture | JEPA — joint embedding predictive | Generative — diffusion + 3D Gaussian splatting |
| Output | Latent representations (invisible — for planning/control) | 3D visual worlds (visible — for navigation/editing) |
| Stage | Research-first (no product yet) | Product-first (Marble shipping since Nov 2025) |
| Revenue model | TBD — long-term scientific project | Freemium SaaS + enterprise (Autodesk integration) |
| Compute footprint | LeWM: 15M params, 1 GPU, hours | Marble: large-scale generation infrastructure |
| Open research | V-JEPA 2, VL-JEPA, LeWM — all open-source | No full architecture paper; commercial product |
| Robotics play | Direct control via latent planning (V-JEPA 2-AC) | Indirect — generate sim environments via NVIDIA Isaac |
| Creative play | None — can't render visuals | Strong — Chisel editor, 3D world creation |
| Biggest strength | Compute efficiency + physical understanding | Immediate utility + visual quality |
| Biggest weakness | Can reason about worlds it can't show you | Can show you worlds it may not understand |
The Complementarity Thesis
These companies may be building different layers of the same stack. A complete world model system needs both capabilities: understanding (what will happen if the robot pushes this object?) and rendering (what does this room look like from the robot's perspective?). AMI's representations could feed World Labs' renderer, or vice versa.
2. World Labs Marble: Deep Dive
Architecture and Capabilities
Marble generates persistent, editable 3D environments from multimodal inputs. While World Labs hasn't published a full architectural paper, the technical approach is clear from their product.
Input modalities: Text prompts, photographs, videos, panoramas, or coarse 3D layouts. Marble is a truly multimodal world model — any of these inputs can seed a 3D world.
3D Representation: Gaussian Splats
Marble's primary output format is 3D Gaussian splatting. Instead of traditional polygon meshes, scenes are represented as millions of semitransparent 3D Gaussians, each defined by position, scale, color (with spherical harmonics for view-dependent appearance), and opacity.
The rendering pipeline projects these Gaussians onto the camera plane and alpha-composites them, enabling real-time, photorealistic rendering from any viewpoint. This approach was pioneered by 3D Gaussian Splatting for Real-Time Radiance Field Rendering (Kerbl et al., 2023) and Marble scales it to AI-generated worlds.
The Chisel Editor
Marble includes a hybrid editing interface called Chisel. Users draw rough spatial layouts (walls, floors, objects as blocks), add natural language descriptions for each element, and Marble fills in photorealistic visual detail. This coarse-to-fine workflow — human intent at the structural level, AI generation at the detail level — is a practical solution to the control problem in generative AI.
Export Formats: Gaussian splats (highest fidelity), triangle meshes (including collider meshes for physics simulation), or video (rendered walkthroughs from specified camera paths).
Marble for Robotics: NVIDIA Isaac Integration
Perhaps the most significant capability for our field: Marble worlds can be imported into NVIDIA Isaac Sim for robotics training:
- Describe an environment in text or provide a photo
- Marble generates a 3D world with physics-compatible meshes
- Import into Isaac Sim as a simulation environment
- Train robotic agents in this generated world
This pipeline dramatically reduces the cost of creating diverse simulation environments — a major bottleneck in sim-to-real robotics research.
3. LeWorldModel: This Week's Breakthrough
Why LeWM Changes the Landscape
LeWorldModel (March 23, 2026) is the first JEPA that trains stably end-to-end from raw pixels — no stop-gradients, no EMA, no pretrained encoders, no multi-term losses.
For the intermediate reader, this matters because previous JEPA world models (like DINO-WM) required pretrained DINOv2 features — meaning they weren't truly learning from scratch. LeWM uses a ViT-Tiny encoder (~5M params) and a transformer predictor (~10M params), totaling ~15M parameters, trained from pixel input with just two loss terms.
The engineering angle: LeWM achieves 96% success rate on Push-T (block manipulation) while planning in <1 second. Foundation-model-based alternatives take 48× longer. The code is open source, building on stable-worldmodel for environment management and evaluation.
What it validates: AMI's thesis that energy-based world models can work efficiently from raw sensory input — not just from pretrained features. This is the missing engineering proof that JEPA scales down as well as it scales up (V-JEPA 2 at 1.2B parameters).
4. The Post-Sora Generative Landscape
Sora's Shutdown and What It Means
On March 24, 2026, OpenAI discontinued Sora — shutting down the video generation platform and unwinding a $1B Disney deal. The reason: generative video consumed too much compute relative to its revenue potential.
For the world models field, this is a watershed. The most well-resourced generative video model in the world couldn't sustain itself commercially. This doesn't invalidate all generative world models (Marble generates 3D environments, not video — a different problem with different economics), but it confirms that pixel-level video simulation faces a fundamental cost problem.
What Remains: Veo and Open Source
Veo 3.1 (Google, January 2026) pushes to 4K with reference-image conditioning. Google has deeper pockets and more infrastructure patience than OpenAI, so Veo may survive where Sora couldn't.
Open-source video generation is thriving: LTX 2.3 (Lightricks, 22B params, 4K, open-source desktop editor), Helios (Peking U / ByteDance / Canva, 14B, real-time at 19.5 FPS on H100), and HunyuanVideo WorldPlay (Tencent, with RL post-training code for interactive world models at 24 FPS).
Genie: The Interactive Frontier
Genie (Google DeepMind, 2024) demonstrated early interactive capabilities — generating playable 2D game environments from images. Scaling this to 3D, physically-consistent interactive worlds remains the open frontier for generative approaches.
5. Robotics-Focused World Models
DayDreamer: Real-World Robot Learning
DayDreamer (Wu et al., 2022) showed that Dreamer-style world models can train robots in the real world within hours. The robot alternates between brief real-world interactions (collecting data) and extended imagination episodes (training the policy in the world model).
TD-MPC2: Scaling Model-Based Control
TD-MPC2 (Hansen et al., 2024) scales model-based RL to hundreds of millions of parameters across 80+ continuous control tasks. The key design choice: keep everything in latent space — no pixel reconstruction, just latent dynamics and trajectory optimization.
TD-MPC2 demonstrates that model-based RL follows scaling laws similar to language models: bigger models, more diverse training tasks, better zero-shot transfer.
Self-Improving World Models (ASIM)
From the ICLR 2026 RSI Workshop (our W12 coverage): ASIM (OpenReview) pairs forward world models with inverse models for self-improvement through cycle-consistency, enabling self-supervised improvement with 50%+ less data.
R2-Dreamer: Decoder-Free World Models
R2-Dreamer (March 18, 2026) proposes a decoder-free MBRL framework using a Barlow Twins-inspired redundancy-reduction objective. On DeepMind Control Suite and Meta-World, R2-Dreamer matches DreamerV3 and TD-MPC2 while training 1.59× faster. Notably, it excels on tasks with tiny task-relevant objects — exactly where decoder-based methods waste capacity.
6. Emerging Techniques: Flow-Matching and Hybrids
Flow-Matching / Rectified Flow
A key technical trend making generative world models faster: flow matching (Lipman et al., ICLR 2023) learns a direct transport path between noise and data distributions, avoiding the many small steps required by diffusion models. Rectified flow (Liu et al., ICLR 2023) straightens these paths further, enabling few-step generation. The combination proved its commercial viability in Stable Diffusion 3 (Esser et al., 2024), which uses rectified flow transformers to achieve high-resolution image synthesis with fewer sampling steps than traditional diffusion.
For world models, this means: real-time or near-real-time generation of new environmental states — critical for interactive applications where latency matters.
Hybrid Architectures
The most promising direction may be combining approaches:
- Energy-based encoders (JEPA/LeWM-style) for perception and state estimation
- Flow-based or diffusion decoders for visual rendering when needed
- Latent dynamics models (RSSM as in DreamerV3, TD-MPC style) for temporal prediction
- Planning modules that operate in the shared latent space
No single system currently implements this full stack, but the components exist. Integration is the engineering challenge for 2026–2027.
Landscape Summary
| Approach | Key Players | Strength | Limitation | This Week |
|---|---|---|---|---|
| Generative 3D | World Labs (Marble) | Persistent, editable, exportable 3D worlds | No physical dynamics — static environments | Strongest generative play after Sora's exit |
| Video foundation | Google (Veo 3.1), open-source (LTX, Helios) | Photorealistic, implicit physics | Passive, physically inconsistent, expensive | Sora killed — field loses its flagship |
| Energy-based | AMI Labs, Meta (V-JEPA 2), LeWM | Data-efficient, planning-ready, compute-light | No visual generation — representations only | LeWM proves end-to-end training from pixels |
| Robotics-focused | DayDreamer, TD-MPC2, R2-Dreamer | Real-world deployment, imagination-based training | Task-specific, limited generalization | R2-Dreamer: decoder-free, 1.59× faster than DreamerV3 |
| Hybrids / flow-based | Emerging research | Speed + quality, real-time interaction potential | Early stage, no dominant architecture | — |
Connecting the Threads: RSI Meets World Models
Readers following our W10–W12 series on recursive self-improvement will recognize familiar failure modes in the world models landscape. Representation collapse in JEPA (the encoder mapping everything to a constant) is structurally identical to reward hacking in self-play (the agent exploiting a shortcut instead of genuinely improving). Both are cases where the learning objective is technically satisfied while the system learns nothing useful.
The solutions rhyme too. LeWM's SIGReg regularizer forces distributional structure on the latent space — preventing the encoder from collapsing. Verification-based self-training (STaR, ReST) forces correctness structure on generated solutions — preventing the model from reward-hacking. R2-Dreamer's Barlow Twins objective reduces redundancy in learned representations, echoing how diversity-promoting mechanisms prevent mode collapse in self-play.
ASIM (from our W12 RSI Workshop coverage) makes the connection explicit: it applies RSI principles — cycle-consistency between forward and inverse models — directly to world model self-improvement. This is the intersection of our W10–W12 and W13–W15 arcs: self-improving world models that bootstrap their own understanding of physical reality.
The practical implication for our notebooks: the regularization techniques we implement in NB 00 (SIGReg-style collapse prevention) are the world model analog of how verification filtering prevents reward hacking in W11's STaR notebook. Same principle, new domain, same engineering instinct. NB 01 then extends this with latent-space planning via CEM and Model Predictive Control.
Key Takeaways
- AMI Labs and World Labs represent two sides of the same coin — understanding vs. generation — each backed by ~$1B and legendary founders
- World Labs Marble is the most commercially advanced generative world model, with real products and Autodesk integration
- LeWorldModel proves that JEPA works from raw pixels on a single GPU — removing the biggest engineering barrier to energy-based world models
- Sora's shutdown shows that pixel-level video world simulation faces a fundamental cost problem, strengthening the case for latent-space approaches
- Robotics world models (DayDreamer, TD-MPC2, R2-Dreamer) are converging on decoder-free, latent-space architectures
- The hybrid thesis — energy-based encoders + generative decoders — is gaining traction as the most complete architecture
- The RSI throughline: Collapse prevention in world models mirrors reward-hack prevention in self-play — same challenge, same engineering principles, connecting our entire W10–W15 content arc
References
- AMI Labs TechCrunch coverage — Funding details
- World Labs / Marble — Product page
- World Labs raises $200M from Autodesk
- LeWorldModel: Stable End-to-End JEPA from Pixels — Maes et al. (2026)
- R2-Dreamer: Redundancy-Reduced World Models — Morihira et al. (2026)
- OpenAI Discontinues Sora — Variety (2026)
- Marble: A Multimodal World Model — World Labs (2025)
- Simulate Robotic Environments Faster with NVIDIA Isaac Sim and World Labs Marble — NVIDIA (2025)
- 3D Gaussian Splatting for Real-Time Radiance Field Rendering — Kerbl et al. (2023)
- V-JEPA 2 — Bardes et al. (2025)
- DayDreamer: World Models for Physical Robot Learning — Wu et al. (2022)
- TD-MPC2: Scalable, Robust World Models for Continuous Control — Hansen et al. (2024)
- Self-Improving World Models via Asymmetric Forward-Inverse Consistency — Liu et al. (ICLR 2026 Workshop RSI)
- Flow Matching for Generative Modeling — Lipman et al. (ICLR 2023)
- Flow Straight and Fast: Learning to Generate and Transfer Data with Rectified Flow — Liu et al. (ICLR 2023)
- Scaling Rectified Flow Transformers for High-Resolution Image Synthesis — Esser et al. (2024)
- DreamerV3: Mastering Diverse Domains through World Models — Hafner et al. (2023)
- From Video Generation to World Model — CVPR 2025 Tutorial
- LeWM GitHub Repository — Official code
Stay connected:
- 📧 Subscribe to our newsletter for updates
- 📺 Watch our YouTube channel for AI news and tutorials
- 🐦 Follow us on Twitter for quick updates
- 🎥 Check us on Rumble for video content