Inside Marble-Like Architectures: From Pixels to 3D Worlds
Trend tutorial on World Models -- focusing on Worldlabs' Marble
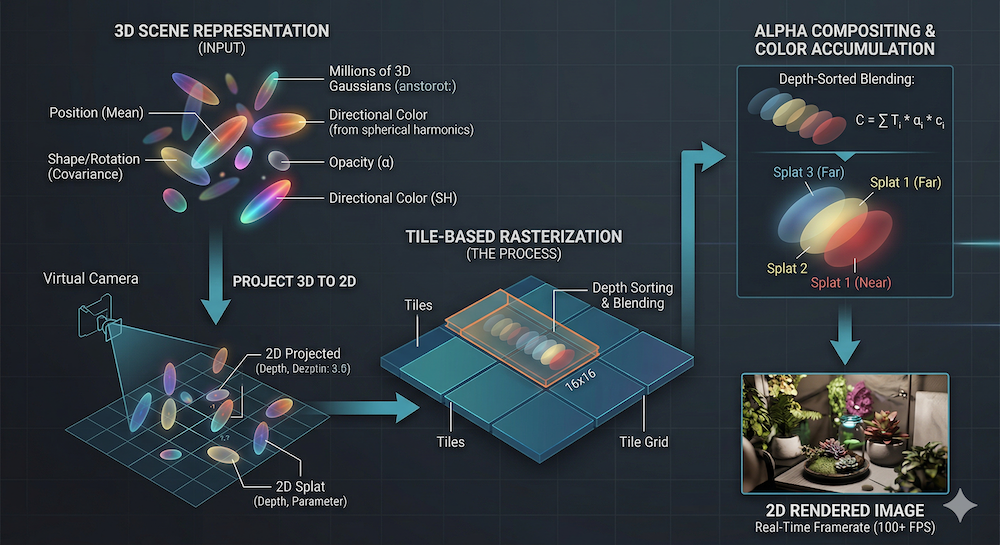
Figure: illustration of 3D Gaussian "Splatting"
W14 Trend Tutorial · Advanced (ML Practitioner) · April 2026
Research Area: 3D Generation, World Models
Companion Notebooks
| Notebook | Focus | Difficulty |
|---|---|---|
| NB 00: 3DGS From Scratch | Differentiable 3DGS renderer + optimization, pure NumPy | Intermediate |
| NB 01: Image-to-Gaussian Baseline | Minimal encoder → Gaussian decoder, toy Marble-like pipeline, NumPy CPU-only | Intermediate |
| NB 02: Novel View Synthesis | Render predicted Gaussians from new camera angles, quality-vs-angle evaluation | Intermediate |
| NB 03: Multi-View Aggregation | Fuse multiple predicted views into a single consistent 3D scene | Advanced |
Why This Matters Now
Last week's W13 trend tutorial explored world models from the energy-based perspective: JEPA encodes the world, LeWM compresses it, both sit at the latent-reasoning frontier. This week, we flip the problem: given a latent representation or a single image, how do we generate a navigable 3D world?
Enter Marble, World Labs' flagship product. In November 2025, they made it public alongside the World API — a system that converts text, images, video, and multi-view inputs into explorable 3D environments. On the surface, it's a powerful product. But its internals remain closed.
This tutorial reconstructs what a Marble-like architecture likely looks like using open research as our foundation. We rely on three recent papers that tackle image-to-3D generation via Gaussian splatting:
- DiffusionGS (arXiv:2411.14384): single-stage, end-to-end diffusion-to-Gaussians
- Gen-3Diffusion (arXiv:2412.06698): iterative 2D↔3D synergy with multi-view consistency
- Complete Gaussian Splats from Single Image (arXiv:2508.21542): latent diffusion for view-complete reconstruction
We also anchor ourselves in the foundational 3D Gaussian Splatting paper by Kerbl et al., which redefined how we render 3D scenes efficiently.
The honest edge: we show readers how we reason about closed systems from first principles and the open literature. We don't pretend to know Marble's internals -- we don't. Instead, we build the reasoning skills to infer likely architectures and validate them against product behavior. In any case, feedback is always welcome.
The Image-to-3D Generation Pipeline
Modern systems that turn images into 3D worlds follow a conceptual pipeline, though implementations vary:
- Input Encoding: Process the input (image, text, multi-view set) through domain-specific encoders
- Latent Representation: Compress into a learnable latent space
- 3D Structure Prediction: Generate Gaussian parameters, mesh, or volumetric representation
- Rendering & Iteration: Project to 2D, evaluate consistency, optionally refine
This differs fundamentally from video generation systems like Sora. Video models like Sora generate frames sequentially in time, relying on temporal consistency constraints. Image-to-3D systems generate persistent geometry — a single 3D representation that can be rendered from infinite viewpoints. Once you have the 3D structure, rendering is deterministic; it's not a learned generative process.
The key insight: geometry is the bottleneck. Color and appearance can be interpolated or filled in. Geometry — the spatial structure of occlusions, depth, and layout — must be either directly predicted or inferred through multi-view consistency.
3D Gaussian Splatting: The Rendering Foundation
To understand image-to-3D pipelines, we need the rendering backbone: 3D Gaussian Splatting (3DGS).
What It Is
Instead of representing a scene as a neural field (NeRF) or a mesh, 3DGS represents the scene as a set of 3D Gaussians. Each Gaussian has:
- Position: — center of the Gaussian in world space
- Covariance: — defines the shape and orientation (ellipsoid). Stored as a quaternion + scale for efficiency.
- Opacity: — how transparent or opaque the Gaussian is
- Color: represented via spherical harmonics (SH) coefficients, enabling view-dependent color
Why 3DGS Won Over NeRF
NeRF renders by querying a neural network for every pixel: given a ray (origin + direction), call the network to predict color and density. This is expressive but slow. Rendering a 1080p image requires millions of forward passes.
3DGS replaces this with rasterization: project each 3D Gaussian onto the 2D image plane, depth-sort them, and alpha-composite. This is a GPU-native operation — the same rasterization pipeline used in traditional graphics. As a result, 3DGS achieves 100+ FPS on consumer hardware, while NeRF requires seconds per frame.
The trade-off: 3DGS is explicit and discrete (millions of Gaussians), while NeRF is implicit and continuous (a learned function). But for most scenes, 3DGS quality rivals or exceeds NeRF while being orders of magnitude faster.
The Rendering Process (Simplified)
- Project: For each Gaussian, project and onto the image plane (2D Gaussian)
- Sort: Order Gaussians by depth (back-to-front)
- Composite: For each pixel, accumulate color and opacity from front to back:
The rendering is differentiable: gradients flow backward through projection and composition, enabling optimization of Gaussian parameters from rendered images.
For deeper technical detail, see the W14 basics article (published Friday) and the original paper by Kerbl et al.
From Image to Gaussians: Three Architectural Approaches
The core challenge: given a single image (or text, or multi-view set), predict thousands of Gaussian parameters (position, covariance, opacity, SH coefficients).
Three recent works offer distinct solutions:
1. DiffusionGS: Single-Stage End-to-End
Paper: Baking Gaussian Splatting into Diffusion Denoiser
Approach:
- Patchify the input image into tokens
- Feed through a Vision Transformer backbone
- Append a Gaussian decoder that outputs per-pixel Gaussian maps
- Single diffusion reverse process directly outputs Gaussians
Key Innovation: The authors develop a "Splatter Image" decoder — a lightweight module that converts transformer features into explicit Gaussian parameters. Reference-Point Plücker Coordinates (RPPC) condition the decoder on camera intrinsics, helping the model predict depth-aware geometry.
Performance:
- ~6 seconds on A100 GPU (single pass)
- 2.20 dB PSNR improvement over prior work on objects
- Can export mesh or splat directly
Pros: Fast (single stage), scalable, clean architecture Cons: No iterative refinement, may miss fine detail
2. Gen-3Diffusion: Iterative 2D↔3D Synergy
Paper: Realistic Image-to-3D Generation via 2D & 3D Diffusion Synergy
Approach:
- 2D stage: Pre-trained image diffusion model generates multi-view images from the input
- 3D stage: Diffusion model directly regresses 3D Gaussians from the denoised multi-view images
- Loop: render the predicted Gaussians, feed back to 2D diffusion for consistency refinement
- Repeat 2–4 times for convergence
Key Insight: The 2D model brings generalization (trained on billions of images). The 3D model enforces consistency (all views must be renderable from the same geometry). By alternating, each stage's strength compensates for the other's weakness.
Performance:
- ~22 seconds on consumer GPU (iterative)
- Handles clothed avatars, diverse objects
- High-fidelity texture and geometry
Pros: Multi-view consistency, leverages 2D priors, iterative refinement Cons: Slower (iterative), requires both 2D and 3D diffusion modules
3. Complete Gaussian Splats from Single Image: Latent Diffusion
Paper: Complete Gaussian Splats from a Single Image with Denoising Diffusion Models
Approach:
- Variational AutoReconstructor learns a compact latent space for 3D Gaussian parameters
- Latent diffusion model denoises in this latent space
- Decoder (Splatter Image) maps latents back to explicit Gaussians
- Classifier-free guidance enables control over completeness vs. diversity
Key Insight: Working in latent space reduces computational cost and allows the model to reason about structure more abstractly. The VAE learns to compress 3D structure into a compact representation.
Performance:
- Faster than Gen-3Diffusion (latent-space diffusion)
- Handles occluded and out-of-frustum regions probabilistically
- Diverse outputs possible via classifier-free guidance
Pros: Efficient (latent), handles occlusion, diverse sampling Cons: Requires VAE pretraining, potential latent bottleneck
Comparison Table
| Approach | Architecture | Speed | Multi-View Consistency | Iterative | Flexibility |
|---|---|---|---|---|---|
| DiffusionGS | Single-stage (Transformer + decoder) | Fast (≈6s) | Implicit (per-image Gaussian maps) | No | Limited by single-pass inference |
| Gen-3Diffusion | 2D + 3D diffusion loop | Moderate (≈22s) | Explicit (2D↔3D feedback) | Yes (2–4 rounds) | High (iterative refinement) |
| Complete Splats | VAE + latent diffusion | Fast (latent) | Implicit (VAE bottleneck) | No | Medium (guidance-based) |
Reconstructing Marble's Likely Architecture
Marble doesn't publish technical details. But its product behavior and public statements give us clues. Let's reason backward.
Observable Facts
-
Outputs Gaussian splats — World Labs offers Gaussian splat exports. This means the underlying representation is explicit 3D Gaussians, not implicit fields.
-
Multimodal inputs — Marble accepts text, images, panoramas, multi-view sets, video. Different modalities require modality-specific encoders that feed into a shared latent space.
-
Chisel editor decouples structure and style — Users first place coarse 3D shapes (boxes, planes), then apply a prompt to "fill in details." This suggests a two-stage pipeline: geometry generation, then appearance refinement.
-
Real-time generation capability (RTFM) — The World API generates 3D worlds "on demand." While not millisecond-latency, the system must be reasonably efficient — likely single-pass or a fixed small number of iterations.
-
Persistent, editable worlds — Once generated, users can extend worlds by clicking unexplored regions. This implies the 3D representation is explicit and modifiable (consistent with splats, not implicit fields).
-
Multimodal export — Gaussian splats, meshes, videos. Suggests the core representation is geometry-first (Gaussians), with rendering/conversion modules for other formats.
Likely Architecture
Input stage: Modality-specific encoders (text, image CNN, video temporal encoder) → fused latent representation
Geometry stage: Transformer or diffusion module predicts Gaussian parameters from latent representation. If iterative, likely limited to 1–2 refinement steps (speed constraint).
Appearance stage: Optional second pass or integrated prediction of SH coefficients, leveraging multimodal context for lighting and style.
Export stage: Rasterize splats, convert to mesh (ball-pivoting or Poisson), or render videos.
The structure-style decoupling in Chisel suggests Marble might use a factorized representation: explicit geometry (Gaussian positions, scales) separate from appearance (opacity, SH). This is architecturally simpler than joint prediction and aligns with the DiffusionGS or Gen-3Diffusion patterns.
Critical caveat: This is informed speculation, not fact. Marble's internals are proprietary. We reason about likely designs because they're consistent with open research and product behavior. The real system may differ significantly.
The AMI–Marble Convergence
Last week's W13 landscape basics framed a key tension: AMI and similar approaches (JEPA, LeWM) compress the world into latent space for reasoning. World Labs' Marble decompresses latent space into explicit 3D worlds for rendering and interaction.
These are complementary:
- Understand (AMI): encode rich visual observations into abstract spatial reasoning
- Render (Marble): decode reasoning into navigable 3D environments
The future likely needs both. An agent needs to understand a scene (JEPA) to reason about it, but also to visualize its predictions (Marble) — either for human oversight or as part of its internal world model. We're witnessing the emergence of bidirectional world models: encode for reasoning, decode for rendering.
What We Build This Week
We've outlined the theory. Now let's implement.
Notebook 00: 3DGS from Scratch
Pure NumPy implementation of 3D Gaussian Splatting. No PyTorch, no CUDA — just linear algebra and Python.
Why NumPy? Forces understanding. Every matrix multiplication, every projection, every alpha-composite step is visible. No auto-grad magic. Bugs become lessons. The code runs on any machine.
What you'll implement:
- 3D Gaussian representation (position, covariance, opacity, color)
- Projection to 2D image plane
- Depth sorting (back-to-front)
- Differentiable alpha compositing
- Optimization loop: render → compare to target → update parameters
Outcome: A toy scene (a few hundred Gaussians), optimized to match a target image.
Notebook 01: Image-Conditioned Gaussian Generation
Build a toy Marble-like pipeline: image input → Gaussian prediction → novel view synthesis.
Architecture:
- Simple CNN encoder on input image
- MLP decoder predicting Gaussian parameters
- Train on image pairs with pose variation
- Eval: given one view, render a novel view
Why simplified? Full DiffusionGS / Gen-3Diffusion requires heavy machinery (diffusion, transformers). Our toy version isolates the core: can a simple encoder-decoder learn to predict view-consistent geometry from an image? If so, the machinery scales up.
Outcome: Render the same scene from multiple angles, starting from a single reference image.
Looking Ahead
We've grounded the image-to-3D problem in open research, reconstructed Marble's likely design, and previewed two hands-on implementations.
The generative side of world models is where the product excitement lives. But theory and practice are tightly coupled. Coming up in this series: we shift focus to the architectures powering these systems — are transformers the right backbone for spatial and physical reasoning, or is the field moving beyond attention? We survey State Space Models, equivariant networks, and the hybrid designs emerging at the frontier. For now, focus on the geometric foundation.
Read the papers, run the notebooks, and build intuition. World models are the next frontier, and understanding their rendering backbone is essential.
References
- Kerbl et al. (2023). 3D Gaussian Splatting for Real-Time Radiance Field Rendering. ACM TOG.
- Cai et al. (2024). Baking Gaussian Splatting into Diffusion Denoiser for Fast and Scalable Single-stage Image-to-3D Generation. arXiv:2411.14384.
- Xue et al. (2024). Gen-3Diffusion: Realistic Image-to-3D Generation via 2D & 3D Diffusion Synergy. T-PAMI.
- Liao et al. (2025). Complete Gaussian Splats from a Single Image with Denoising Diffusion Models. arXiv:2508.21542.
- Mildenhall et al. (2020). NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis. ECCV 2020.
- Goyal et al. (2023). I-JEPA: Joint-Embedding Predictive Architecture. Meta AI Research.
- Liang et al. (2025). LeWorldModel: Latent-space World Model Learning. arXiv:2603.19312.
- World Labs. Marble: A Multimodal World Model.
- World Labs. Announcing the World API.
- World Labs. Generating Bigger and Better Worlds (RTFM).
Published: April 2, 2026
Topic: Generative 3D, World Models, Gaussian Splatting
Level: Advanced ML practitioners
Companion: W13 Energy-Based World Models
Stay connected:
- 📧 Subscribe to our newsletter for updates
- 📺 Watch our YouTube channel for AI news and tutorials
- 🐦 Follow us on Twitter for quick updates
- 🎥 Check us on Rumble for video content