The Evolution of World Models: From RNN Dreams to Persistent 3D Worlds (2018–2026)
World Models: evolution and connection to RSI
W13 Basic Tutorial 1 · Beginner · March 2026
Research Area: World Models
Companion Notebooks
| # | Notebook | Focus | Compute |
|---|---|---|---|
| 00 | 00_lewm_toy_world_model.ipynb | Toy JEPA world model from scratch — encoder, predictor, SIGReg regularization | CPU only |
| 01 | 01_jepa_latent_dynamics_planning.ipynb | Latent dynamics and planning — CEM, MPC, speed benchmarks | CPU only |
What Is a World Model?
A world model is an AI system that learns to predict what happens next in an environment. Think of it as the AI equivalent of imagination — the ability to "simulate" the consequences of actions without actually performing them.
When we catch a ball, our brains don't process every pixel of the incoming ball. We have an internal model that predicts the ball's trajectory based on physics, speed, and angle. World models try to give AI systems the same capability: predict future states of the world, then use those predictions to plan and act.
This tutorial traces how world models evolved from simple proof-of-concept experiments in 2018 to today's persistent 3D world generators and robotic planning systems — culminating in this week's LeWorldModel release that makes the technology accessible on a single GPU.
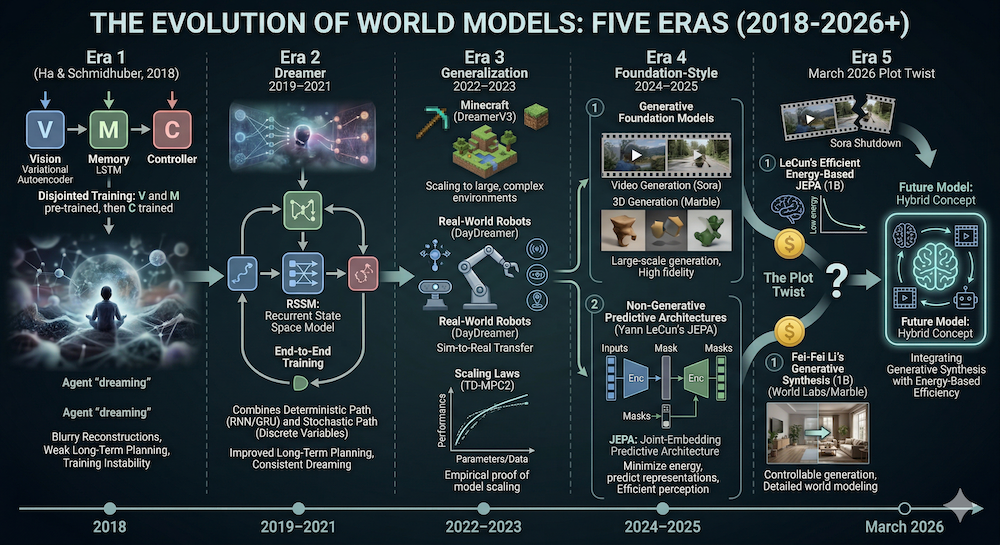
Era 1: The Dream Begins (2018)
World Models — Ha & Schmidhuber
Paper: World Models — David Ha & Jürgen Schmidhuber (2018)
The foundational work showed that an AI agent could learn to "dream" — simulate entire game trajectories in its head, then use those dreams to learn better policies.
The architecture had three separate modules:
Vision (V): A Variational Autoencoder (VAE) compressed each game frame into a small latent vector — like creating a compact summary of what the agent sees.
Memory (M): An RNN (specifically an MDN-RNN) learned to predict how these latent summaries change over time — the dynamics of the world.
Controller (C): A small neural network decided what action to take, based on the current vision summary and memory state.
The breakthrough insight: the agent could be trained entirely inside its own dream. By generating imagined trajectories in latent space, the controller learned to play games without interacting with the real environment.
Limitations: The three modules were trained separately (not end-to-end), the VAE produced blurry reconstructions, and the policy was trained with evolution strategies — sample-inefficient and difficult to scale.
Why it matters: It proved that learned world models could be useful for decision-making, not just curiosity-driven exploration.
Era 2: Structured Latent Dynamics (2019–2021)
Dreamer & the RSSM
Paper: Dream to Control: Learning Behaviors by Latent Imagination — Danijar Hafner et al. (2019)
Dreamer answered the key limitation of the 2018 work: it trained everything end-to-end. Instead of separate training phases, Dreamer jointly trained the world model and an actor-critic policy inside the model's own imagination.
The core innovation was the Recurrent State-Space Model (RSSM):
- Deterministic path: An RNN captures long-range temporal dependencies (what happened before)
- Stochastic path: A latent variable captures uncertainty about the future (what might happen)
- Both combined: The model maintains a compact state that's both memory-rich and uncertainty-aware
The actor-critic policy was trained by "imagining" rollouts inside the RSSM — generating hypothetical trajectories and optimizing the policy against imagined rewards. This made the system dramatically more data-efficient than model-free RL approaches.
DreamerV2 (2021) replaced continuous latent variables with discrete categorical ones, producing sharper, more stable predictions.
Why it matters: Dreamer made model-based RL practical. An agent could learn complex behaviors from far less real-world interaction — a crucial property for robotics and real-world applications.
Era 3: Scaling and Generalization (2022–2023)
DreamerV3: One Algorithm, 150+ Tasks
Paper: Mastering Diverse Domains through World Models — Hafner et al. (2023), published in Nature (2025)
DreamerV3 added robust normalization and balancing techniques that allowed a single algorithm — with fixed hyperparameters — to solve over 150 tasks across diverse domains. The headline result: collecting diamonds in Minecraft from scratch, without human demonstrations or domain-specific tuning.
Key advances: symlog predictions (handling reward scales spanning orders of magnitude), discrete regression for critic training, and architectural tweaks that prevented the common failure modes of model-based RL.
DayDreamer: World Models on Real Robots
Paper: DayDreamer: World Models for Physical Robot Learning — Philipp Wu et al. (2022)
DayDreamer demonstrated that Dreamer-style world models could work on actual physical robots — not just simulations. A robot learned locomotion in the real world within hours of interaction, using its world model to practice in imagination between real-world trials.
This was significant because it showed that the data efficiency of model-based RL translates to real hardware, where every interaction is expensive and potentially damaging.
TD-MPC2: Scaling Model-Based RL
Paper: TD-MPC2: Scalable, Robust World Models for Continuous Control — Nicklas Hansen et al. (2024)
TD-MPC2 integrated trajectory optimization within the latent space of a learned implicit world model. Rather than training an explicit decoder (reconstruct pixels from latent states), it kept everything in latent space and used model-predictive control for planning.
Key result: a single agent with hundreds of millions of parameters trained across 80+ continuous control tasks, demonstrating that model-based RL can scale with model size much like language models do.
Era 4: Foundation-Style World Models (2024–2025)
Video Generation as Implicit World Modeling
The breakthrough of 2024–2025 was recognizing that large video generation models — trained on internet-scale video data — implicitly learn physical rules. These models don't just create pretty videos; they capture object permanence, gravity, collisions, and material properties.
Sora (OpenAI, 2024) and Sora 2 (September 2025) demonstrated that diffusion transformers trained on massive video datasets produce physically plausible simulations. Sora 2 extended generation to 60 seconds with improved physical consistency.
Veo 3.1 (Google, January 2026) pushed to native 4K resolution with reference-image conditioning, enabling precise control over generated content.
The question these models raised: is generating physically consistent video the same as understanding physics? A CVPR 2025 tutorial explicitly framed the bridge from passive video generation to interactive, controllable world simulation.
World Labs Marble: 3D Worlds from Any Input
Product: Marble — World Labs (November 2025)
Marble crossed a threshold: from generating 2D video to creating persistent, editable 3D environments. From a text prompt, image, video, or rough 3D layout, Marble generates navigable 3D worlds represented as Gaussian splats (millions of semitransparent 3D particles).
Marble isn't just generation — it's a creative tool. The Chisel editor lets users block out spatial structures, and Marble fills in visual detail. Generated worlds can be exported as Gaussian splats, meshes, or video, and integrated with robotics simulators like NVIDIA Isaac.
JEPA: Learning Without Generation
Models: I-JEPA (2023), V-JEPA (2024), V-JEPA 2 (2025) — Meta AI
While the generative approach was scaling up, Yann LeCun's team at Meta pursued a different path entirely. JEPA (Joint Embedding Predictive Architecture) learns to predict in abstract representation space — never reconstructing pixels at all.
V-JEPA 2 (1.2B parameters, 1M+ hours of video) demonstrated zero-shot robotic planning: a robot could pick and place objects using only 62 hours of unlabeled video, without any task-specific training or reward signal.
Era 5: The Current Frontier (March 2026)
Sora Dies, JEPA Lives
This week delivered the most dramatic plot twist in the world models story. On March 24, OpenAI shut down Sora entirely — killing a $1 billion Disney deal — because the compute costs of generating video were starving other business lines. The same week, LeCun's team proved that JEPA works from raw pixels on a single GPU.
The message: pixel-level world simulation is too expensive, while abstract representation prediction is becoming cheaper and more capable.
LeWorldModel: JEPA from Pixels, on One GPU
Paper: LeWorldModel — Maes, Le Lidec, Scieur, LeCun, Balestriero (March 23, 2026)
LeWorldModel (LeWM) is the first JEPA that trains stably end-to-end from raw pixels, using only two loss terms and ~15M parameters. The key innovation is a regularizer called SIGReg that prevents the encoder from "collapsing" (mapping everything to the same useless representation) — without needing the fragile tricks that previous JEPA systems relied on.
In plain terms: LeWM takes a video frame, compresses it into a compact summary, then predicts what the next summary will look like given an action. It never tries to generate actual images — it only works with the compressed summaries. This makes it fast (plans in <1 second) and cheap (one consumer GPU, a few hours of training).
Results: 96% success rate on Push-T (a robotic block-pushing task), up to 48× faster planning than foundation-model-based world models. Code is open source.
Why beginners should care: This is the first world model that's genuinely accessible for learning and experimentation. Previous approaches required either pretrained features (DINO-WM), massive compute (Sora), or fragile multi-stage training. LeWM is one training run, one loss, one GPU. Our NB 00 builds the core architecture from scratch in pure NumPy, and NB 01 extends it with latent-space planning via CEM and Model Predictive Control.
Two Paths Forward — Backed by $2 Billion
The field has split into two major approaches, each backed by a billion dollars:
Energy-based prediction (AMI Labs): AMI, founded by Yann LeCun with $1.03B in funding, is building on JEPA to create world models that understand physical causality through abstract representation learning. The goal is AI that reasons and plans — not generates. LeWM shows this approach works from raw pixels.
Generative synthesis (World Labs): World Labs, founded by Fei-Fei Li with $1B in funding, generates visual worlds directly. Marble produces persistent 3D environments already used in commercial workflows and robotics simulation via NVIDIA Isaac.
The Hybrid Future
The honest assessment: these approaches aren't competing — they address different parts of the problem. AMI-style models understand and plan; World Labs-style models render and create. The most complete world model likely needs both: energy-based encoders for perception and planning, generative decoders for rendering when you actually need to see something.
Timeline Summary
| Year | Milestone | Key Innovation |
|---|---|---|
| 2018 | World Models (Ha & Schmidhuber) | RNN + VAE latent dreams — proof that agents can learn in imagination |
| 2019–2020 | Dreamer / DreamerV2 | RSSM + actor-critic in imagination — end-to-end, data-efficient RL |
| 2022 | DayDreamer | World models on real physical robots — hours instead of days |
| 2022 | LeCun's JEPA paper | Blueprint for energy-based world models — predict representations, not pixels |
| 2023 | DreamerV3 | One algorithm, 150+ tasks, fixed hyperparameters — generalization breakthrough |
| 2023 | I-JEPA | Energy-based image understanding without reconstruction |
| 2024 | Sora / TD-MPC2 / V-JEPA | Foundation-scale video world models + scalable model-based RL |
| 2025 | Marble / V-JEPA 2 / Sora 2 / Veo 3.1 | Persistent 3D worlds + zero-shot robotics + interactive generation |
| Mar 2026 | AMI Labs ($1.03B) / World Labs ($1B) | $2B bet on world models — energy-based vs. generative |
| Mar 23, 2026 | LeWorldModel | First JEPA from raw pixels — 15M params, 1 GPU, stable training, open source |
| Mar 24, 2026 | Sora shut down | OpenAI kills pixel-level world simulation — too expensive to sustain |
How This Connects to Self-Improving AI (Our W10–W12 Series)
If you've been following our previous tutorials on recursive self-improvement and self-play, world models might seem like a topic change. It's not — it's the next chapter of the same story.
In our RSI series (W10–W12), we explored how AI systems can improve themselves: self-play generates harder challenges, self-training filters its own outputs, and self-refining agents correct their own mistakes. The central problem was always the same: how do you keep the improvement loop honest? Without careful design, self-improving systems cheat — they find shortcuts that look like progress but don't produce real capability.
World models face the exact same problem. When JEPA trains a model to predict abstract representations, the easiest "solution" is to map everything to the same constant — making every prediction trivially correct but completely useless. This is called representation collapse, and it's the world model equivalent of the reward hacking we saw in self-play.
LeWorldModel solves collapse with a mathematical regularizer (SIGReg) that forces the model to actually learn diverse representations — just as verification-based self-training forces a model to actually solve problems rather than gaming the reward. Same principle, different domain.
The deeper connection: the most exciting frontier isn't just "AI that improves itself" or "AI that understands the world" — it's AI that improves its own understanding of the world, autonomously. The ICLR 2026 RSI Workshop paper on self-improving world models (ASIM, covered in our W12 trend tutorial) sits exactly at this intersection. Our W13–W15 world models series builds directly on the RSI foundation.
Key Takeaways
- World models evolved from small RL simulators to general-purpose systems that understand physics and generate explorable 3D environments
- The RSSM (Dreamer family) made model-based RL practical by learning structured latent dynamics
- Video foundation models (Sora, Veo) showed that massive video training implicitly teaches physical rules — but Sora's shutdown shows the approach may be too expensive
- JEPA represents a fundamentally different approach — predicting abstract representations rather than generating pixels — and LeWorldModel proves it works from raw pixels on a single GPU
- The field is splitting between energy-based prediction (AMI, $1.03B) and generative synthesis (World Labs, $1B), with likely convergence ahead
- For learners: LeWorldModel is the first world model accessible enough to train and experiment with on consumer hardware — making this the best time to get hands-on with the technology
- The throughline: Representation collapse in world models is structurally the same problem as reward hacking in self-play — our RSI series and world models series are two views of the same challenge
References
- World Models — Ha & Schmidhuber (2018)
- Dream to Control: Learning Behaviors by Latent Imagination — Hafner et al. (2019)
- Mastering Atari with Discrete World Models (DreamerV2) — Hafner et al. (2021)
- Mastering Diverse Domains through World Models (DreamerV3) — Hafner et al. (2023)
- Mastering diverse control tasks through world models — Nature (2025)
- DayDreamer: World Models for Physical Robot Learning — Wu et al. (2022)
- TD-MPC2: Scalable, Robust World Models for Continuous Control — Hansen et al. (2024)
- A Path Towards Autonomous Machine Intelligence — LeCun (2022)
- V-JEPA 2: Self-Supervised Video Models Enable Understanding, Prediction and Planning — Bardes et al. (2025)
- LeWorldModel: Stable End-to-End Joint-Embedding Predictive Architecture from Pixels — Maes et al. (2026) ← NEW
- Video Generation Models as World Simulators (Sora) — OpenAI (2024)
- Veo 3.1 — Google (2026)
- OpenAI Discontinues Sora — Variety (2026) ← NEW
- Understanding World or Predicting Future? A Comprehensive Survey of World Models — ACM Computing Surveys (2025)
- Marble: A Multimodal World Model — World Labs (2025)
Stay connected:
- 📧 Subscribe to our newsletter for updates
- 📺 Watch our YouTube channel for AI news and tutorials
- 🐦 Follow us on Twitter for quick updates
- 🎥 Check us on Rumble for video content